模型评价指标
分类模型指标
准确率
accuracy:分类正确的样本占总样本个数的比例。import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)精确率
precision:精确率指模型预测为正的样本中实际也为正的样本占被预测为正的样本的比例。from sklearn.metrics import precision_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
# average:'macro','micro','weighted',None
precision_score(y_true, y_pred, average='macro')) # 0.222222召回率
recall:召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例。from sklearn.metrics import recall_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
# average:'macro','micro','weighted',None
recall_score(y_true, y_pred, average='macro')) # 0.222222F1:F1—score是精确率和召回率的调和平均值。评价标准: F1 score越高,说明模型越稳健
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
# average:'macro','micro','weighted',None
f1_score(y_true, y_pred, average='macro')) # 0.222222混淆矩阵
Confusion Matrix:混淆矩阵中的P表示Positive,即正例或者阳性,N表示Negative,即负例或者阴性。
FP - 表示实际为负但被预测为正的样本数量
TN - 表示实际为负被预测为负的样本的数量
TP - 表示实际为正被预测为正的样本数量
FN - 表示实际为正但被预测为负的样本的数量
from sklearn.metrics import confusion_matrix
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
confusion_matrix(y_test,y_pred,labels=[0,1,2])P-R曲线: P-R曲线的横轴是召回率,纵轴是精确率。
P-R曲线上的一个点代表,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
整条P-R曲线是通过将阈值从高到低移动而生成的。
原点附近代表当阈值最大时模型的精确率和召回率。
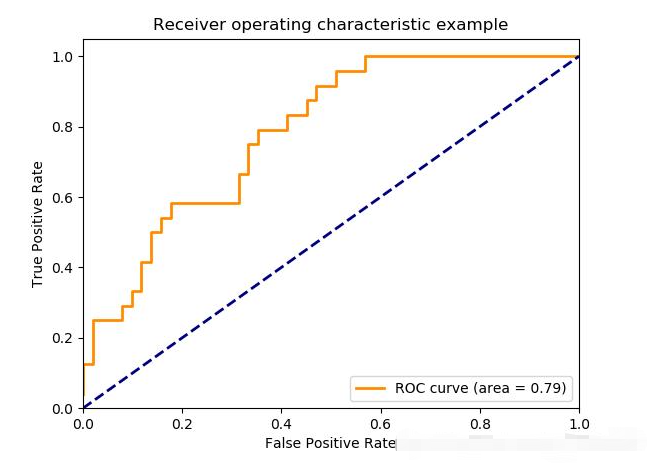
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
import numpy as np
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
precision, recall, _ = precision_recall_curve(y_true, y_pred)
plt.step(recall, precision, color='b', alpha=0.2, where='post')
plt.fill_between(recall, precision, step='post', alpha=0.2, color='b')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('2-class Precision-Recall curve: AP={0:0.2f}'.format(average_precision))